
Shared Memory Program Structure and Coordination Patterns¶
0. Program Structure Implementation Strategy: The basic fork-join pattern¶
The omp parallel pragma on line 21, when uncommented, tells the compiler to fork a set of threads to execute the next line of code (later you will see how this is done for a block of code). You can conceptualize how this works using the following diagram, where time is moving from left to right:
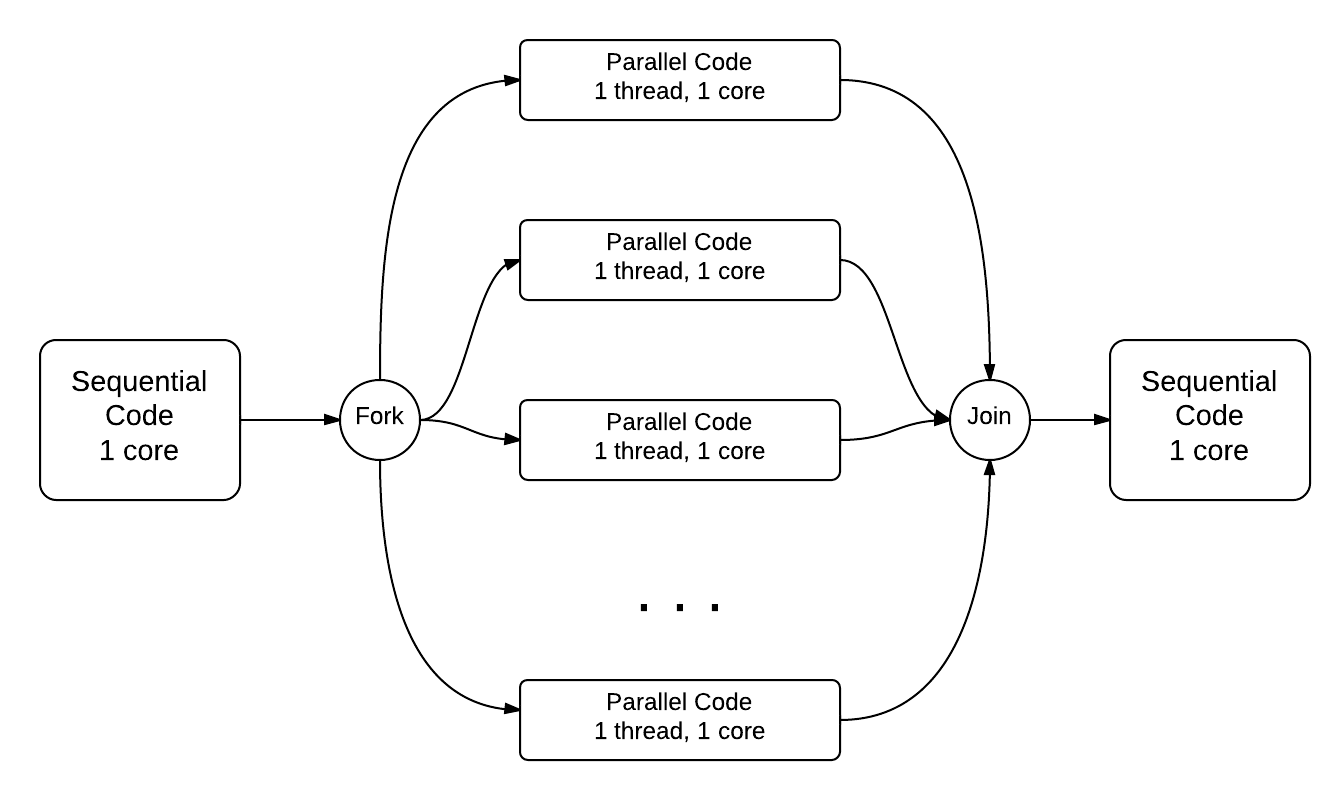
Observe what happens when you have the pragma commented (no fork) and when you uncomment it (adding a fork).
Note that in OpenMP the join is implicit and does not require a pragma directive.
1. Program Structure Implementation Strategy: Fork-join with setting the number of threads¶
This code illustrates that one program can fork and join more than once and that programmers can set the number of threads to use in the parallel forked code.
Note on line 28 there is an OpenMP function called omp_set_num_threads for setting the number of threads to use for each fork, which occur when the omp_parallel pragma is used. Also note on line 35 that you can set the number of threads for the very next fork indicated by an omp_parallel pragma by augmenting the pragma as shown in line 35. Follow the instructions in the header of the code file to understand the difference between these.
2. Program Structure Implementation Strategy: Single Program, multiple data¶
Note how there are OpenMP functions to obtain a thread number and the total number of threads. We have one program, but multiple threads executing in the forked section, each with a copy of the id and num_threads variables. Programmers write one program, but write it in such a way that each thread has its own data values for particular variables. This is why this is called the single program, multiple data (SPMD) pattern.
Most parallel programs use this SPMD pattern, because writing one program is ultimately the most efficient method for programmers. It does require you as a programmer to understand how this works, however. Think carefully about how each thread executing in parallel has its own set of variables. Conceptually, it looks like this, where each thread has its own memory for the variables id and numThreads:
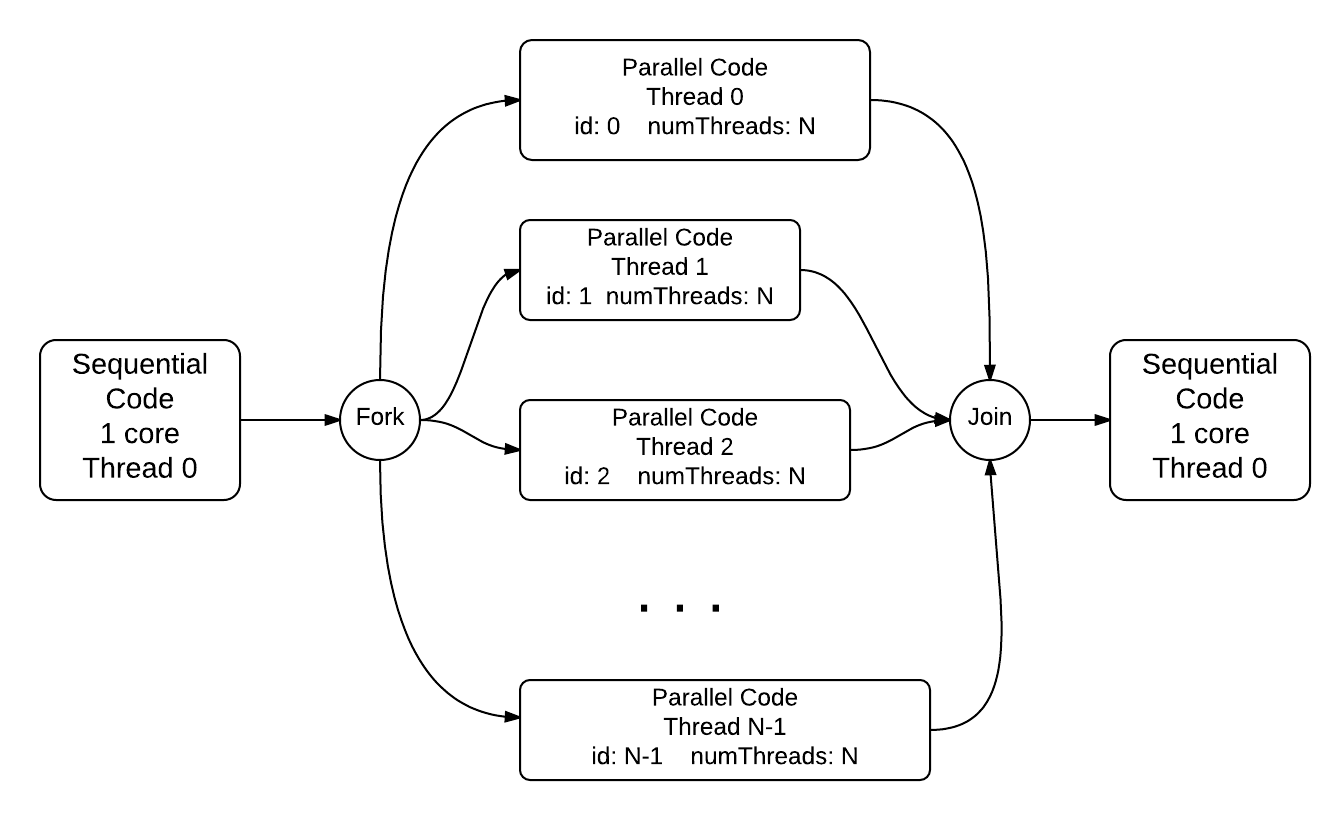
When the pragma is uncommented in the code below, note what the default number of threads is. Here the threads are forked and execute the block of code inside the curly braces on lines 22 through 26. This is how we can have a block of code executed concurrently on each thread.
When you execute the parallel version containing the pragma (uncommenting line 20), what do you observe about the order of the printed lines? Run the program multiple times– does the ordering change? This illustrates an important point about threaded programs: the ordering of execution of statements between threads is not guaranteed. This is also illustrated in the diagram above.
Warning
It is very important to realize that the functions omp_get_thread_num() and omp_get_num_threads() only make sense to be used inside a forked section of code (inside the block indicated by {} just below the pragma line). Outside this block, these functions would return 0 and 1 because thread 0 is the only thread running outside of a forked section of code.
3. Program Structure Implementation Strategy: Single Program, multiple data with user-defined number of threads¶
This code is designed to take one command line argument, from argv[1], on line 27 and use it to set the number of threads. There is a place below the code to change this value in the box provided. Replace 4 with other values for the number of threads to try. This is a useful way to make your code versatile so that you can use as many threads as you would like.
We have a problem!¶
You may not see the bug in this code right away. This illustrates a problem with this type of programming: bugs can be hard to find because sometimes the code seems to run correctly. Try using 10 threads and execute this code several times. What do you notice about the thread number reported? Is there always 0 through 9? Eventually the output should look wrong. Now compare this code to the example 2 above, which is correct. How would you fix this current example 3?
The reason for the bug in the original code is that variables declared outside of the parallel block are shared by all threads. So in this case, each thread was attempting to write to the one data element in memory for the variable called id. This causes them to race to write their value. In contrast, each thread has its own ‘private’ copy of variables declared inside the parallel block. In this case, each thread can then have its own private variable to hold its distinct id value.
Warning
There is a limit to how many threads you should try on a shared memory machine, but it depends on the machine used by this book or your own machine where you try this code. We suggest you limit your choice to 8-16 or less for this example, since they also print out and clutter the screen. You will see later that using too many threads can cause diminishing returns.
4. Coordination: Synchronization with a Barrier¶
The barrier pattern is used in parallel programs to ensure that all threads complete a parallel section of code before execution continues. This can be necessary when threads are generating computed data (in an array, for example) that needs to be completed for use in another computation.
Note what happens with and without the commented pragma on line 31 by uncommenting and running again.
Conceptually, the running code with the pragma uncommented is excuting like this:
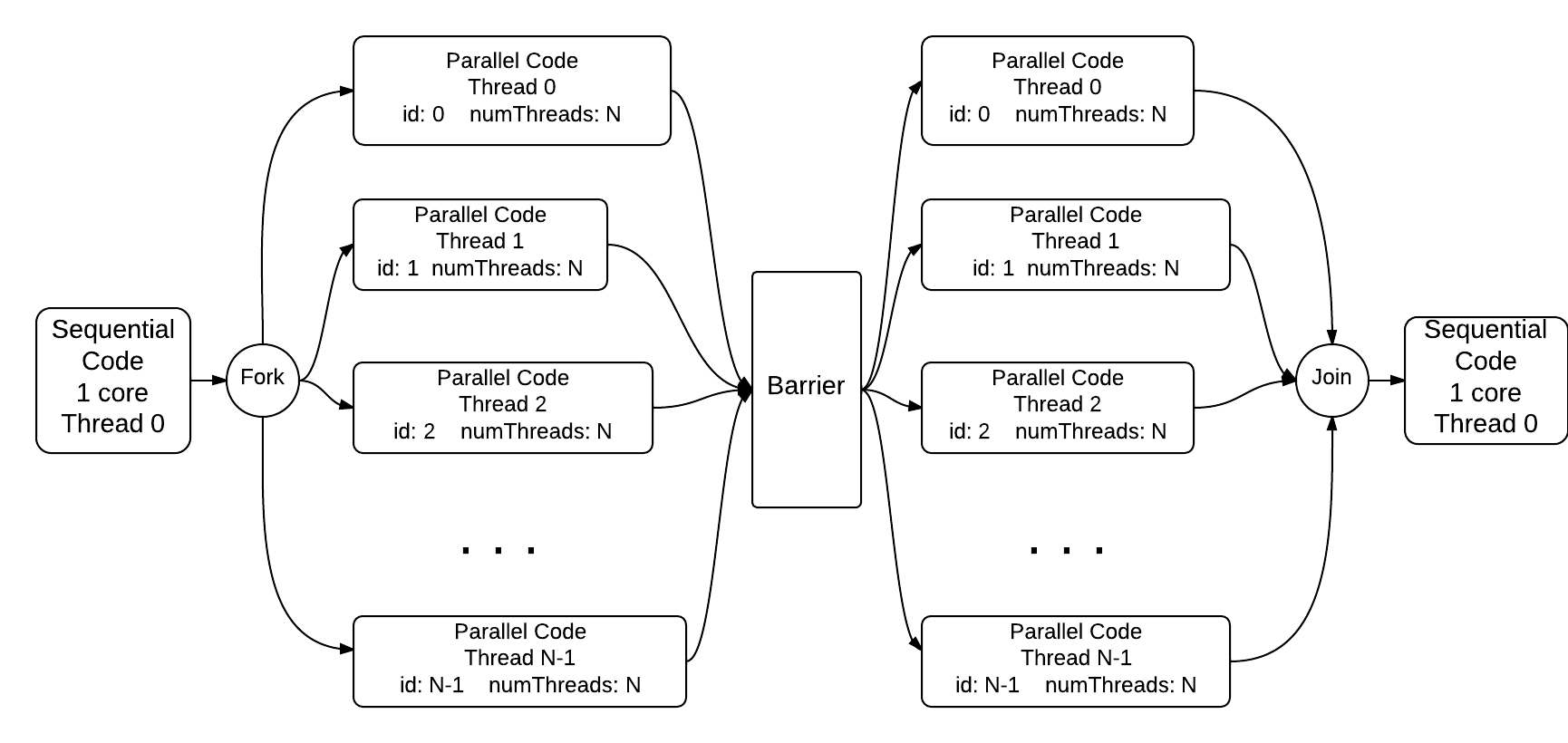
You can explore a bit more by replacing 4 in the command line input with other values for the number of threads.
5. Program Structure: The Conductor-Worker Implementation Strategy¶
Once you have mastered the notion of fork-join and single-program, multiple data, the next common pattern that programmers use in association with these patterns is to have one thread, called the conductor, execute one block of code when it forks while the rest of the threads, called workers, execute a different block of code when they fork. This is illustrated in this simple example (useful code would be more complicated).
See this in action by uncommenting the line with the pragma and re-running the code.
You can also once again experiment with different numbers of threads in the command line argument.
Note
By convention, programmers use thread number 0 as the conductor and the others as the workers.
You may see other words used instead of conductor for this pattern, such as leader. In this book we are trying to eliminate and not use a historical term used that should be recognized as offensive.
T/F From this code, you can deduce that programmers do not control the assignment of thread ids.
or that the OpenMP library is in charge of assigning thread ids.
Summary Overview¶
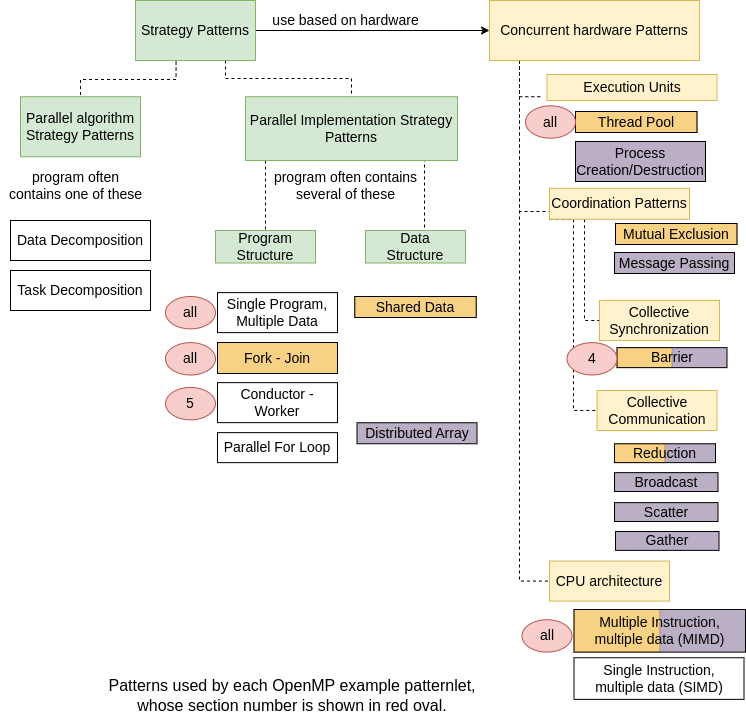
On this page we have begun a journey of exploration of the various patterns found in parallel programs on shared memory machines using the OpenMP library. Below is the portion of the complete parallel patterns diagram that contains the patterns introduced in this subchapter. The number of each section above that corresponds to a particular pattern is shown in a red oval. As you continue on to the next page, the numbers will increase and we will add more red ovals to this picture as we see examples of other patterns.
Note
Interesting points to understand from this:
The OpenMP library and compilers that can recognize the pragmas have the notion of a group of threads, or thread pool, built into every program, thus the reason all of the examples use this.
All OpenMP programs use one program compiled from source files. Thus all OpenMP programs are single program, multiple data (SPMD), where threads may manipulate different data elements stored on memory.
To execute portions of the code in parallel, or concurrently on separate threads, the shared memory system must fork the threads, then join them back when the parallel portion indicated by the block ({}) or by one line of code has completed on all threads. This is why all of the examples use the fork-join pattern.
The underlying shared memory machine that OpenMP code runs on is inherently a MIMD, or multiple-instruction, multiple data machine, so that pattern applies to all examples. Over time in computer science, this has become the predominant architecture that all multicore CPUs employ.